

学生番号
21050010
学科
スーパークリエーター科
AIクリエーター専攻
学年
3年
卒業年度
2025年3月卒業予定
メッセージ
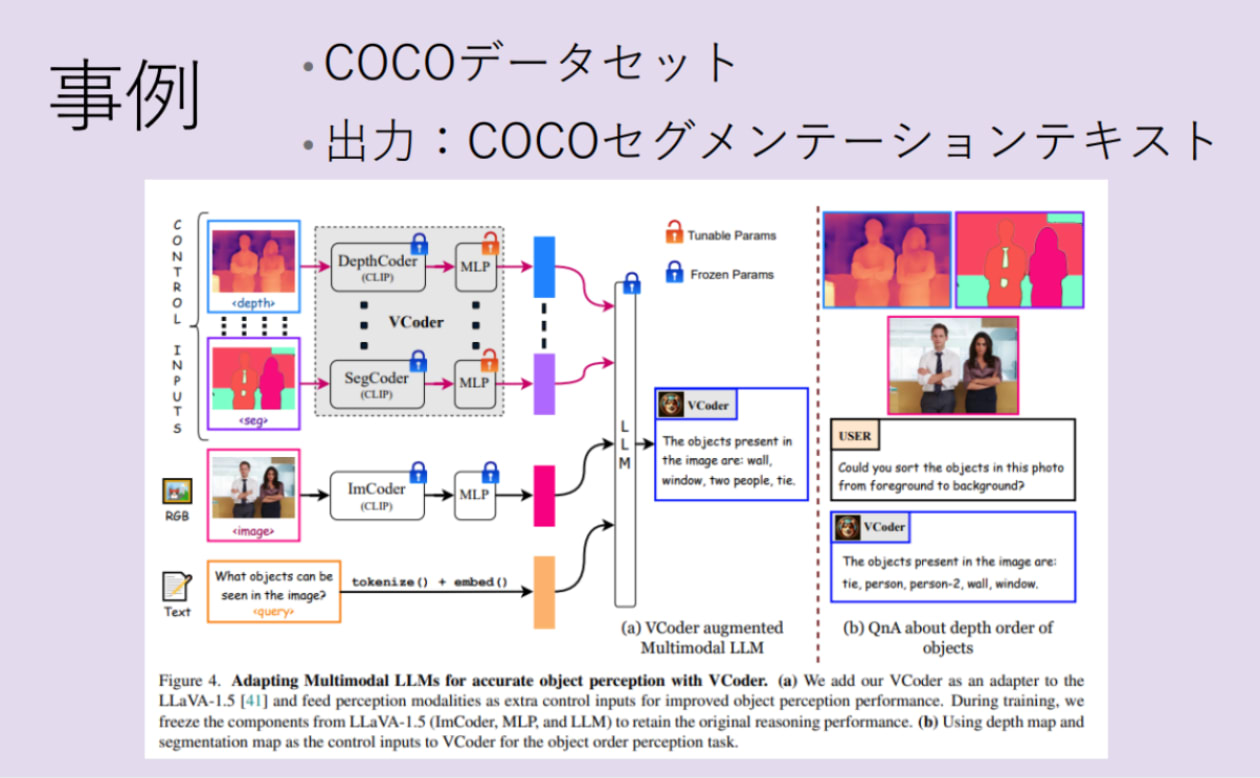
今回のは多用途ビジョンエンコーダを使った マルチモーダル大規模言語モデル(MLLMs)について発表しました。現状、MLLMsは視覚言語に関 するタスクに才能を魅せてきましたが、これらのモデルは単純な物体認証タスクで正確に認識 と数えることしかできないのが弱点になっています。
MLLMsを改善するための施策は次の特徴が持っています。
・モデルにセグメンテーションや深度マップの追加
・高い順位のコンポーネントを認識し、重みの行列 を削減することにより、トランスフォーマー内の 特定レイヤーに集中できる。
この特徴の追加で、モデルの物体レベルの認識を向上し、 追加訓練とパラメータの必要性がなくなったことが判明されました。
これにより、MLLMsのパフォーマンス向上の他に、 複雑な視覚の処理と理解の精度を向上させることが できました。今後認識と推論がより効率な言語モデルを開発される のを期待しています。
21050010
学科
スーパークリエーター科
AIクリエーター専攻
学年
3年
卒業年度
2025年3月卒業予定
メッセージ
今回のは多用途ビジョンエンコーダを使った マルチモーダル大規模言語モデル(MLLMs)について発表しました。現状、MLLMsは視覚言語に関 するタスクに才能を魅せてきましたが、これらのモデルは単純な物体認証タスクで正確に認識 と数えることしかできないのが弱点になっています。
MLLMsを改善するための施策は次の特徴が持っています。
・モデルにセグメンテーションや深度マップの追加
・高い順位のコンポーネントを認識し、重みの行列 を削減することにより、トランスフォーマー内の 特定レイヤーに集中できる。
この特徴の追加で、モデルの物体レベルの認識を向上し、 追加訓練とパラメータの必要性がなくなったことが判明されました。
これにより、MLLMsのパフォーマンス向上の他に、 複雑な視覚の処理と理解の精度を向上させることが できました。今後認識と推論がより効率な言語モデルを開発される のを期待しています。
学生へのメッセージ、スカウトなどは「お問い合わせ」からご連絡ください。

